

Web scraping, it’s a strange term that you may have come across by accident while surfing the tubes, or perhaps you have seen one of the more recent nerdy movies where a hacker has written some code to scrape a website and magically get all of a company’s data.
In simple terms, web scraping is the act of programmatically reading a web page and pulling out the relevant information you are interested in and perhaps using that for other purposes (for the greater good of course).
In this tutorial we are going to use the following:
- Python 3.7 – Any 3.x version should work
- BeautifulSoup (bs4 specifically)
- Requests
- csv (built-in library)
- re (built-in library)
- Google Colaboratory notebook
- A test scraping site from webscraper.io
In this guide we are going to build a web scraper that will read all the products of an e-commerce site which we can save locally for other uses.
Environment Setup
In order to keep the setup and install portion of this guide short, I decided to use a Google Colaboratory notebook. You can accomplish the exact same steps relatively easily in your own python environment, I will touch on how you would potentially deploy a web scraping script at the end of the guide.
Start a new notebook
- Head over to the Google Colaboratory page (you will need a gmail account)
- Login using your gmail details and start a new notebook
- Your new notebook should look something like the screenshot below, I’ve selected the adaptive theme
Next we import our dependencies, you don’t actually have to install anything manually the Colab notebook will do this for you in the backend.
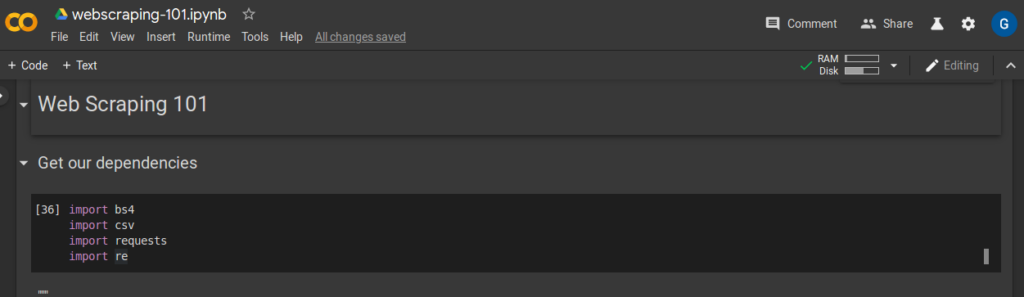
Rather than having a whole guide full of screenshots, I the rest of the guide will have code blocks you can copy and paste. I will only show relevant output as a screen shot if it’s necessary.
The screen shot above added the following two imports, by default you can press crtl+enter to run the cell.
import bs4 import csv import re import requests
In the background the Colab notebook installed these two dependencies for us, if you’re running this in a Jupyter notebook you will have to do that first before this will work.
Inspect the test site
We will be testing our code against a sample web scraping site, kindly provided by the people over at webscraper.io. In order to keep this example as realistic as possible, and to show how you would overcome some common problems we will be using the e-commerce site with pagination links.
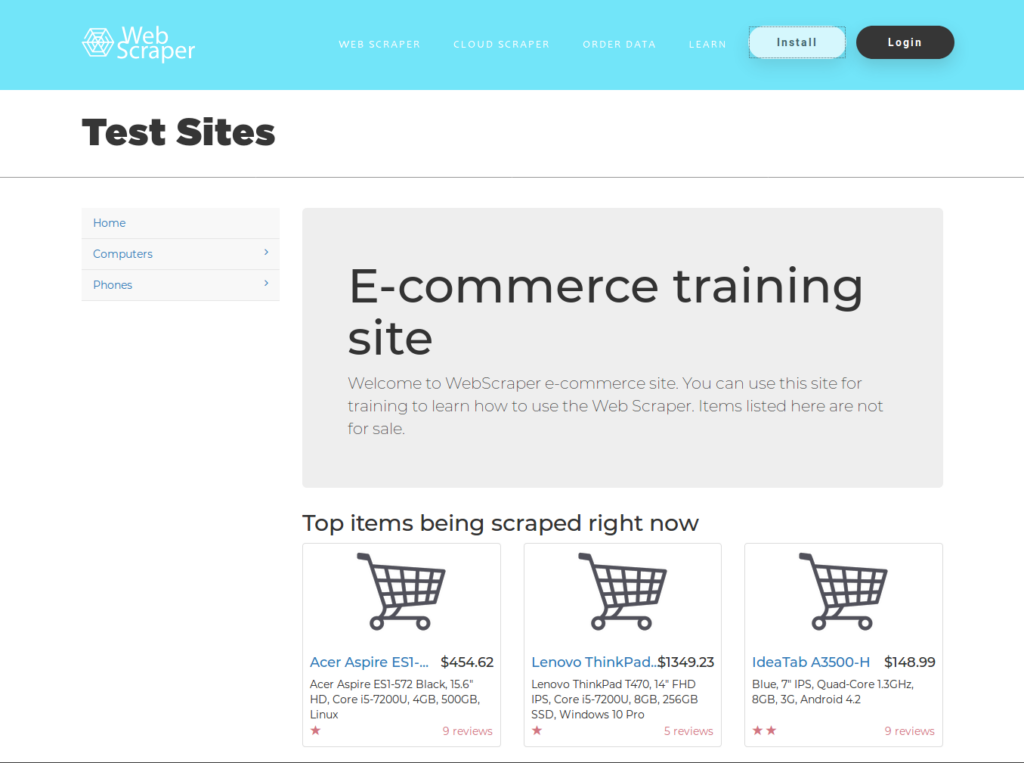
The test site looks very much like an actual e-commerce site would look like, there are a bunch of product listings and some pages have pagination links down the bottom to show additional product pages. We will be focusing specifically on the Laptops sub-section within the Computers top level menu.
Identifying areas of interest
Generally, the first place you want to start when you’re looking to build a web scraper is simply doing an inspect on the actual page to see the HTML. What I am generally looking for are the following items:
- How is the site structured – Are using container DIV’s being used to segment the sections of the page and are there any classes that I can use to get at specific portions of the page
- What part of the site am I interested in capturing, can I see a hierarchical structure to get to those HTML elements
- Does the site have pagination and are the additional page links formatted in a way that I will need to read each element or can I use some kind of incrementing number scheme
Using the above three points, the areas of interest I was able to identify are as follows:
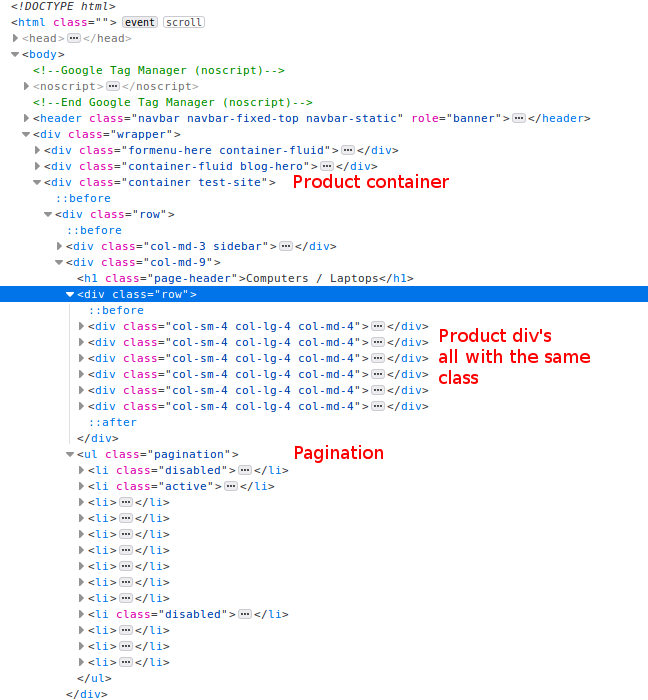
In the code above we can see that this site does use containers to segment the page, this is a good thing and it can make our job a little easier.
<div class="container test-site">
Additionally, it looks like all the products are div’s which are all using the same class details.
<div class="col-sm-4 col-lg-4 col-md-4">...
Lastly, our pagination is inside an unordered list with the class of “pagination”.
<ul class="pagination">
With those three pieces of information I think we are ready to build our web scraper.
Reading a website using Python
Next we have to be able to read that HTML page with Python into some kind of structured format that will allow us to parse the content. We do with two tools that have been created for just that purpose (requests and Beautiful Soup).
import bs4 import requests # this is the page wwe are going to be scraping target = "https://www.webscraper.io/test-sites/e-commerce/static/computers/laptops" raw = requests.get(target).text soup = bs4.BeautifulSoup(raw, 'html.parser')
Let’s take a closer look at lines 5 – 7 in the snippet above.
- Line 5 – This is straight forward, we are defining a variable with the target website url that we want to scrape
- Line 6 – Here we use the requests library to read the HTML from the url we defined in line 5. We specify the text method to this call as we will need it in that format for Beautiful Soup
- Line 7 – Here is where the magic begins, beautiful soup will read our raw html and parse it with a “html.parser”
What we have achieved to this point is reading the HTML of a url into an instance of Beautiful Soup (soup variable). This gives us the ability to leverage all of the goodies provided by Beautiful Soup.
Getting the areas of interest
Next we’ll parse the HTML file and get the three key areas of interest that were identified in the previous section.
import bs4
import requests
# this is the page wwe are going to be scraping
target = "https://www.webscraper.io/test-sites/e-commerce/static/computers/laptops"
raw = requests.get(target).text
soup = bs4.BeautifulSoup(raw, 'html.parser')
# main container div
main_container = soup.find("div", {"class": "container test-site"})
# products
product_list = main_container.findAll("div", {"class": "col-sm-4 col-lg-4 col-md-4"})
# pagination
pagination = main_container.find('ul', {"class": "pagination"})Let’s breakdown the three new lines of code:
- Line 10 – We parse the complete HTML page and look for a div tag with that has a class attribute with the value “container test-site”. As this is really the main area of interest we was to limit any further parsing to a subset of the page, since the page only has a single div that meets that condition we can get away with using the “find” method.
- Line 13 – This line will parse the subset we captured in line 10 and look for all div tags with a class attribute value of “col-sm-4 col-lg-4 col-md-4” which we identified as being the products
- Line 16 – Lastly, we parse the main_container and pull out the pagination ul tag with the class value of “pagination”
Get products and pagination
We now have everything we need to be able to write a script that will capture all product details on this site and progressively move through the additional product pages until we have no additional pages.
import bs4
import requests
import re
# this is the page wwe are going to be scraping
target = "https://www.webscraper.io/test-sites/e-commerce/static/computers/laptops"
raw = requests.get(target).text
soup = bs4.BeautifulSoup(raw, 'html.parser')
def get_products(url: str):
"""
Read html from Webscraper.io and return a product list.
Returns a list of products and a link for the next page (if it exists)
"""
# Read the HTML from the url and get the main container
raw = requests.get(url).text
soup = bs4.BeautifulSoup(raw, 'html.parser')
main_container = soup.find("div", {"class": "container test-site"})
products = main_container.findAll("div", {"class": "col-sm-4 col-lg-4 col-md-4"})
# Check if there is a next page
pagination = main_container.find('ul', {"class": "pagination"})
next = pagination.find('a', {"rel": "next"})
if next:
next = next["href"]
# Iterate through the products and build a list
product_list = [{"Name": p.find("a", {"class": "title"}).text,
"Description": p.find("p", {"class": "description"}).text,
"Price": p.find("h4", {"class": "price"}).text,
"Rating": p.find("p", attrs={"data-rating": re.compile(r".*")})['data-rating']}
for p in products]
return product_list, next
In the snipped above I’ve essentially moved the three variable we had captured different parts of the page into (main_container, products and pagination) into a function. This will allow us to reuse this code to iterate across all pages on the site.
Let take a look at this new snippet in more detail:
Lines 23 to 26
The pagination section of the page is essentially an unordered list of items, we could have approached this one of two ways:
- Read all the elements in the list, work out how many pages there are by reading the last page then come up with some logic look for the currently select page (active) and return the next item in the list.
- Look for a list item with an a tag that has the rel attribute with a value of next. If we don’t find that then we must be on the last page.
The second option was the easiest in my opinion so I went with that, so what we do here is each time the function is called we look through the pagination section looking for a list item that looks like this.
<a href="..." rel="next">»</a>
If we find an item that looks like that then we store the href into the next variable and return it along with the product list. In the event we don’t find it the following piece of code will return None.
pagination.find('a', {"rel": "next"})We will need to accommodate for this when we’re calling this function.
Lines 29 to 35
We are using list comprehension here to build a list of products, our products variable will contain a list of dictionaries.
In general if you want to access the value within an opening and closing tag such as <div>text in here</div> you do so by using the text method as seen throughout lines 29 to 33.
On line 32 I am capturing the value of a custom tag “data-rating” as it contains the value I want to use, here we use the “re” built in library to build a regular expression that will capture all matches.
Lastly we return both a list of products (products variable) and the next page url (next variable).
Putting it all together
import bs4
import csv
import requests
import re
def get_products(url: str):
"""
Read html from Webscraper.io and return a product list.
Returns a list of products and a link for the next page (if it exists)
"""
# Read the HTML from the url and get the main container
raw = requests.get(url).text
soup = bs4.BeautifulSoup(raw, 'html.parser')
main_container = soup.find("div", {"class": "container test-site"})
products = main_container.findAll("div", {"class": "col-sm-4 col-lg-4 col-md-4"})
# Check if there is a next page
pagination = main_container.find('ul', {"class": "pagination"})
next = pagination.find('a', {"rel": "next"})
if next:
next = next["href"]
# Iterate through the products and build a list
product_list = [{"Name": p.find("a", {"class": "title"}).text,
"Description": p.find("p", {"class": "description"}).text,
"Price": p.find("h4", {"class": "price"}).text,
"Rating": p.find("p", attrs={"data-rating": re.compile(r".*")})['data-rating']}
for p in products]
return product_list, next
def main():
# this is the page wwe are going to be scraping
base = "https://www.webscraper.io/"
target = "test-sites/e-commerce/static/computers/laptops"
raw = requests.get(base+target).text
soup = bs4.BeautifulSoup(raw, 'html.parser')
# get first products page
products, next = get_products(base+target)
# Loop through remaining pages
while next:
more_products, next = get_products(base+next)
products += more_products
with open('output.csv', 'w', newline='') as csvfile:
title = ['Name', 'Description', 'Price', 'Rating']
wr = csv.DictWriter(csvfile, fieldnames=title, delimiter='|', quotechar="'", quoting=csv.QUOTE_ALL)
wr.writeheader()
for p in products:
wr.writerow(p)
if __name__ == "__main__":
main()
Putting all the pieces together, we can build a script which grabs the product details and adds and saves the output into a CSV file. Although this is a simple script, it’s some starter code for perhaps something more complicated.
All the code used in this guide is freely available on Github.